Chapter 2 Data sources
2.1 Disester Data
Our disaster Data is coming from The International Disaster Data Center for research on the Epidemiology of Disaster. We downloaded the dataset with default setting. The web page is as shown below:
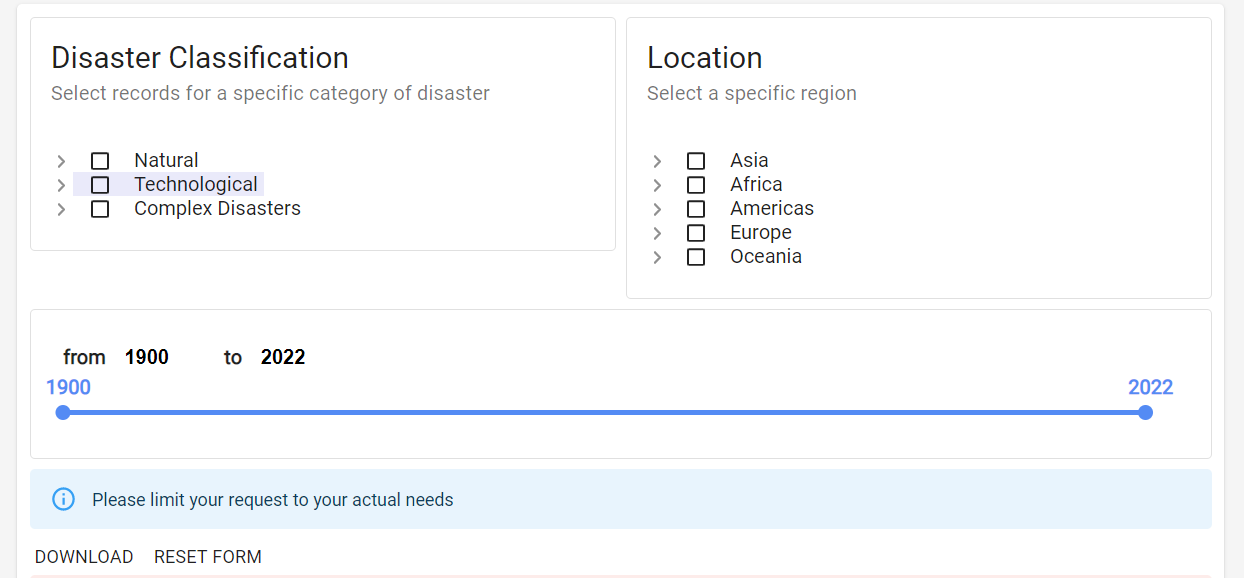
International Disaster Data Center Website
EM-DAT contains essential core data on the occurrence and effects of over 22,000 mass disasters worldwide from 1900 to the present day.
The source of the dataset is described as below, and hence high credibility. > The database is compiled from various sources including UN, governmental and non-governmental agencies, insurance companies, research institutes and press agencies. As there can be conflicting information and figures, CRED has established a method of ranking these sources according to their ability to provide trustworthy and complete data. In the majority of cases, a disaster will only be entered into EM-DAT if at least two sources report the disaster’s occurrence in terms of deaths and/or affected persons.
sprintf('The row number of disaster dataset is %.0f, and the column number is %.0f.', dim(Disaster)[1], dim(Disaster)[2])## [1] "The row number of disaster dataset is 25516, and the column number is 50."# The Names including
print(colnames(Disaster))## [1] "Dis No"
## [2] "Year"
## [3] "Seq"
## [4] "Glide"
## [5] "Disaster Group"
## [6] "Disaster Subgroup"
## [7] "Disaster Type"
## [8] "Disaster Subtype"
## [9] "Disaster Subsubtype"
## [10] "Event Name"
## [11] "Country"
## [12] "ISO"
## [13] "Region"
## [14] "Continent"
## [15] "Location"
## [16] "Origin"
## [17] "Associated Dis"
## [18] "Associated Dis2"
## [19] "OFDA Response"
## [20] "Appeal"
## [21] "Declaration"
## [22] "Aid Contribution"
## [23] "Dis Mag Value"
## [24] "Dis Mag Scale"
## [25] "Latitude"
## [26] "Longitude"
## [27] "Local Time"
## [28] "River Basin"
## [29] "Start Year"
## [30] "Start Month"
## [31] "Start Day"
## [32] "End Year"
## [33] "End Month"
## [34] "End Day"
## [35] "Total Deaths"
## [36] "No Injured"
## [37] "No Affected"
## [38] "No Homeless"
## [39] "Total Affected"
## [40] "Reconstruction Costs ('000 US$)"
## [41] "Reconstruction Costs, Adjusted ('000 US$)"
## [42] "Insured Damages ('000 US$)"
## [43] "Insured Damages, Adjusted ('000 US$)"
## [44] "Total Damages ('000 US$)"
## [45] "Total Damages, Adjusted ('000 US$)"
## [46] "CPI"
## [47] "Adm Level"
## [48] "Admin1 Code"
## [49] "Admin2 Code"
## [50] "Geo Locations"2.2 COVID Data
Our COVID data is from a repository from Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE). We used only the deaths number and read the data directly from the repo.
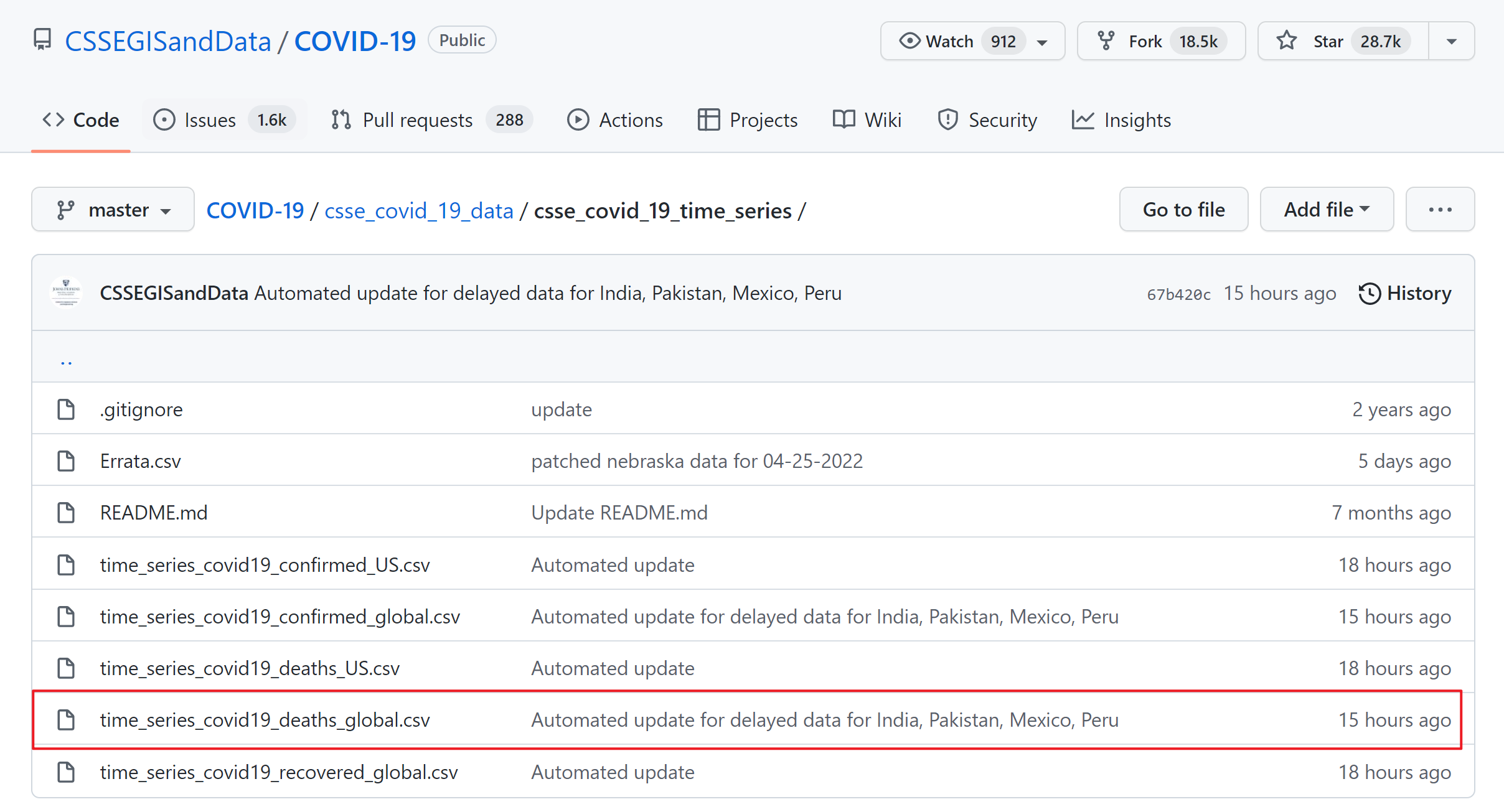 The dataset also supported by the ESRI Living Atlas Team and the Johns Hopkins University Applied Physics Lab (JHU APL), and subject is read in from the daily case report. The time series tables are subject to be updated if inaccuracies are identified in our historical data.
The dataset also supported by the ESRI Living Atlas Team and the Johns Hopkins University Applied Physics Lab (JHU APL), and subject is read in from the daily case report. The time series tables are subject to be updated if inaccuracies are identified in our historical data.
sprintf('The row number of covid dataset is %.0f, and the column number is %.0f.', dim(COVID)[1], dim(COVID)[2])## [1] "The row number of covid dataset is 284, and the column number is 837."# The Names including
print(colnames(COVID)[1:20])## [1] "Province.State" "Country.Region" "Lat" "Long"
## [5] "X1.22.20" "X1.23.20" "X1.24.20" "X1.25.20"
## [9] "X1.26.20" "X1.27.20" "X1.28.20" "X1.29.20"
## [13] "X1.30.20" "X1.31.20" "X2.1.20" "X2.2.20"
## [17] "X2.3.20" "X2.4.20" "X2.5.20" "X2.6.20"And all the later columns are time series data up to now. Each column represent the total death number up to that day.
2.3 GDP Data
Our GDP data is downloaded from The World Bank. We used the world development indicators database, which is the primary World Bank collection of development indicators, compiled from officially recognized international sources. And it presents the most current and accurate global development data available, and includes national, regional and global estimates.
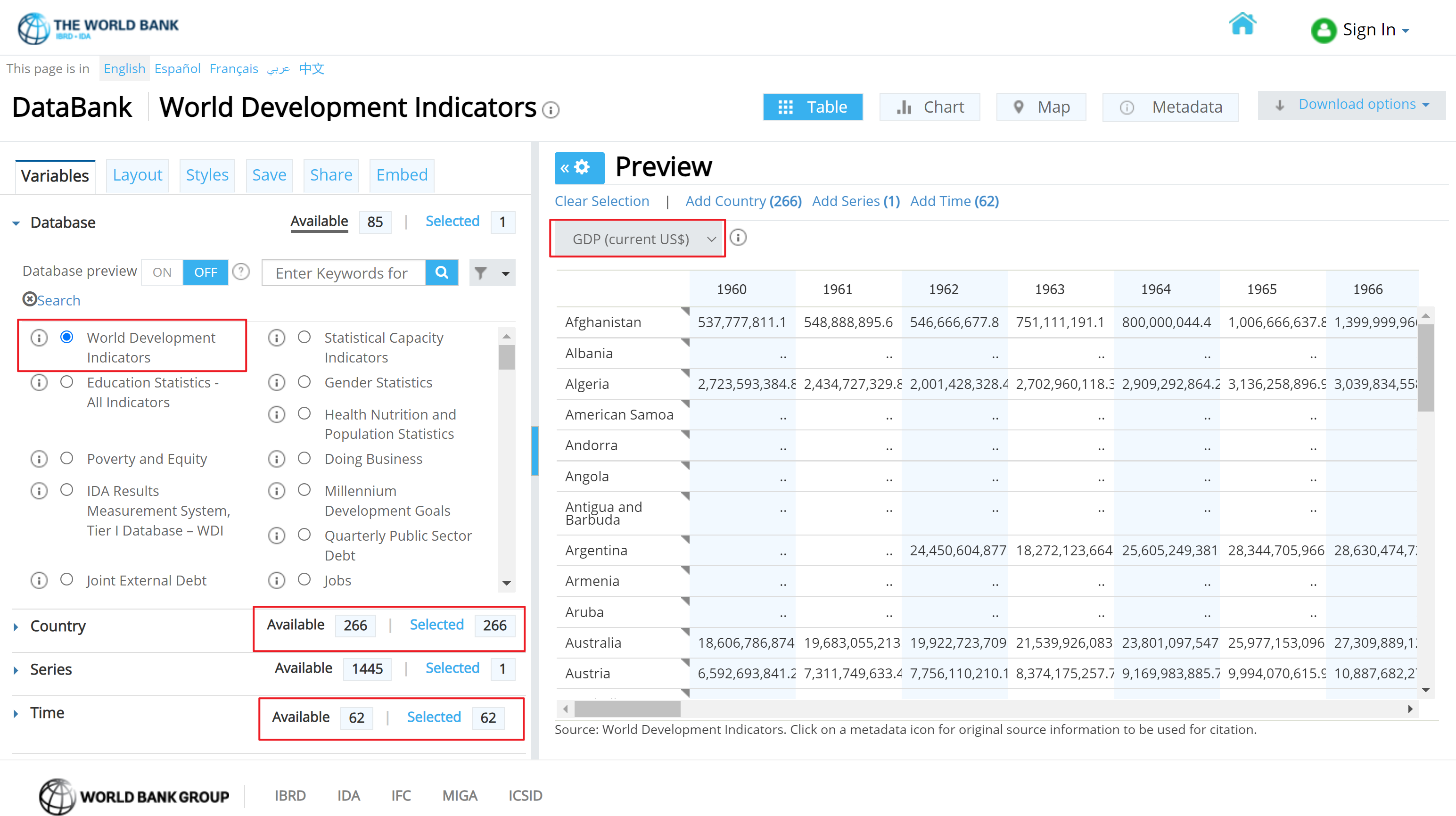 As shown above, we include all Countries and Time(Years) available, and GDP is what we need.
As shown above, we include all Countries and Time(Years) available, and GDP is what we need.
sprintf('The row number of GDP dataset is %.0f, and the column number is %.0f.', dim(GDP)[1], dim(GDP)[2])## [1] "The row number of GDP dataset is 271, and the column number is 66."# The Names including
print(colnames(GDP)[1:20])## [1] "ï..Series.Name" "Series.Code" "Country.Name" "Country.Code"
## [5] "X1960..YR1960." "X1961..YR1961." "X1962..YR1962." "X1963..YR1963."
## [9] "X1964..YR1964." "X1965..YR1965." "X1966..YR1966." "X1967..YR1967."
## [13] "X1968..YR1968." "X1969..YR1969." "X1970..YR1970." "X1971..YR1971."
## [17] "X1972..YR1972." "X1973..YR1973." "X1974..YR1974." "X1975..YR1975."All the later columns are time series data up to now.